Machine Reading Comprehension (MRC) is a Natural Language Understanding problem that aims to automatically understand the meaning of human-generated text.
The goal of “understanding” a piece of text is too arbitrary to define directly as a computational problem. Therefore, MRC is generally modelled as a set of tasks where the objective is to create computational models that can answer input queries when given some reference textual passage.
A model’s language understanding ability can be demonstrated by its ability to answer various questions about the passage, which require an understanding of its meaning and the ability to reason over facts within the text.
MRC is frequently used to solve Question Answering (QA), which is a complex problem that requires advanced understanding and reasoning abilities. Although the two tasks have some basic differences in their motivations, they are often used almost synonymously.
Task formats for Machine Reading Comprehension
The survey paper Neural Machine Reading Comprehension: Methods and Trends gives an overview of some common formats that are used to train and evaluate Machine Reading Comprehension models.
1. The Cloze Task
Given a textual context and a question statement with a missing word, the goal is to identify the missing word by understanding the context. The missing word can be selected from the context or it may be a completely new word.
The CNN and Daily Mail dataset introduced in Teaching Machines to Read and Comprehend is one example benchmark for this task.

Figure 1: An example of the cloze task. The correct answer is January.
2. Multiple Choice Answer Selection
Given a textual context, a question and multiple answer choices; the goal is to select the choice which best answers the given question. This also a common format is real-life tests and exams.
There are a number of datasets that evaluate performance on this task.
The ARC and RACE datasets utilise questions from real-life exams.
MCTEST evaluates performance in a more open-domain setting by answering questions about fictional stories.
The DREAM dataset evaluates the ability to answer questions by reading human-human dialogues.
ReClor evaluates the ability to perform complicated logical reasoning to answer a question.
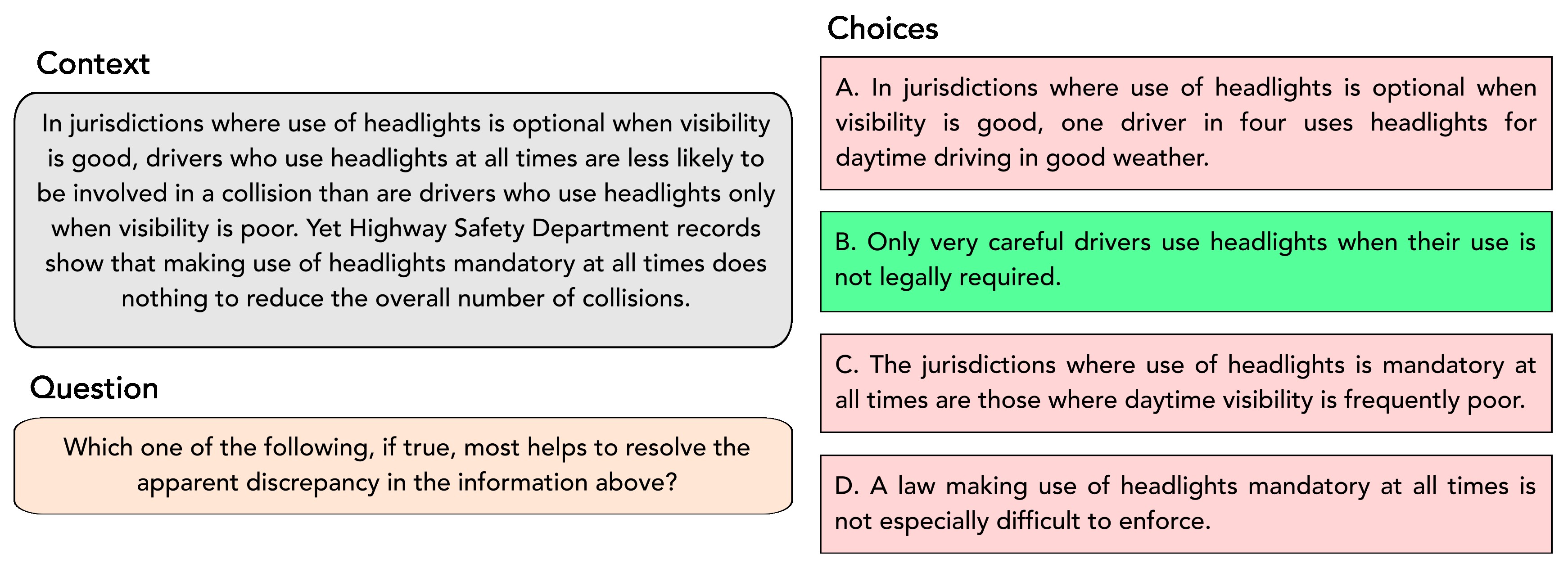
Figure 2: An example multiple-choice question from the ReClor dataset.
3. Answer Span Extraction
Given a question and some textual context, the goal is to extract a contiguous span from the text which answers the question.
This can be modelled as a sequence labelling task where we try to classify each token, or a boundary selection task where we only try to predict the start and end tokens for the span.
This task became popularised in 2016 with the release of the SQuAD dataset, the first large and high-quality dataset for this format. Questions in SQuAD cover a large number of general topics from Wikipedia, thus providing a benchmark for open domain question answering.
Another dataset for this task format is NewsQA, which covers questions related to news from CNN.

Figure 3: Example from the SQuAD 2.0 dataset. Source
4. Free-Form Answer Generation
This is similar to the span extraction task, except for the restriction that the answer may not be a span from the given context. Thus, given a question and context, the model has to generate a unique answer from scratch. This is the most challenging of the Reading Comprehension tasks and also the most general one.
The answer may be constructed via a purely generative approach, utilising an architecture like Sequence to Sequence or a generative language model like GPT to perform Natural Language Generation.
Instead of a purely generative approach, a hybrid approach can also be used. In S-NET, the authors first use an extractive model to find an answer span in the context, then condition on the span to generate a unique answer.
A popular dataset for this type of format is MS MARCO.
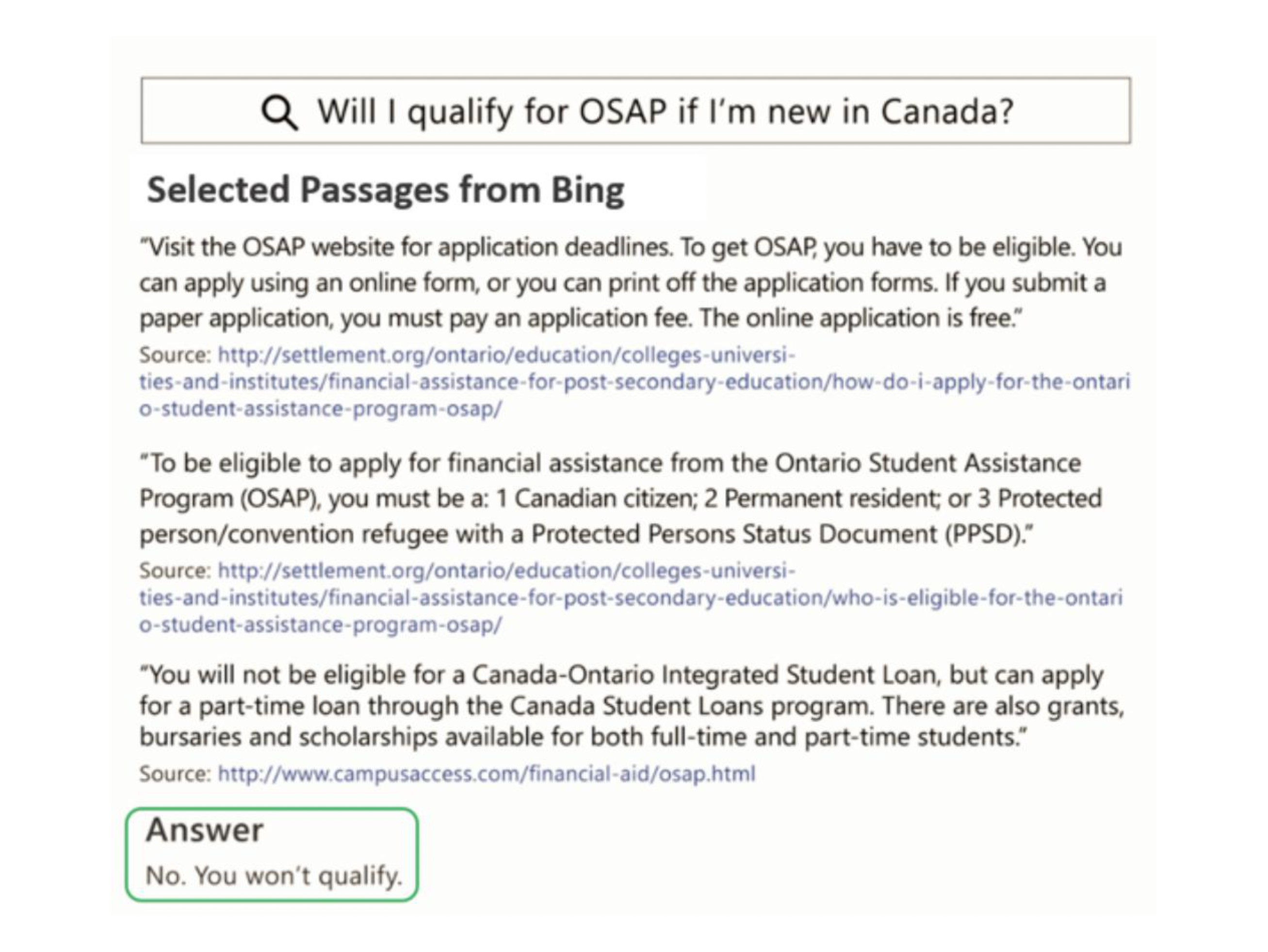
Figure 4: Example from the MS MARCO dataset. Source
Relationship with Question Answering
Since many Machine Reading Comprehension tasks are in the form of answering a given question, it tends to be used almost synonymously with Question Answering (QA) in the literature. However, the end goals are different for both.
As mentioned in this article and also in this survey paper, the goal of MRC is to achieve ‘understanding’ of a given text, while the goal of Question Answering is to simply answer a given question.
Thus, while MRC can be used to solve some forms of Question Answering tasks, it is also applicable to a wider range of non-QA tasks. This is demonstrated in Ask Me Anything: Dynamic Memory Networks for Natural Language Processing and The Natural Language Decathlon: Multitask Learning as Question Answering, where authors model a wide variety of practical tasks as Reading Comprehension.
Generally, QA techniques that rely on understanding a provided context or text passages extracted via information retrieval methods, will fall under the class of Machine Reading Comprehension.
Thus, Reading Comprehension is just one approach to answer question among many others.
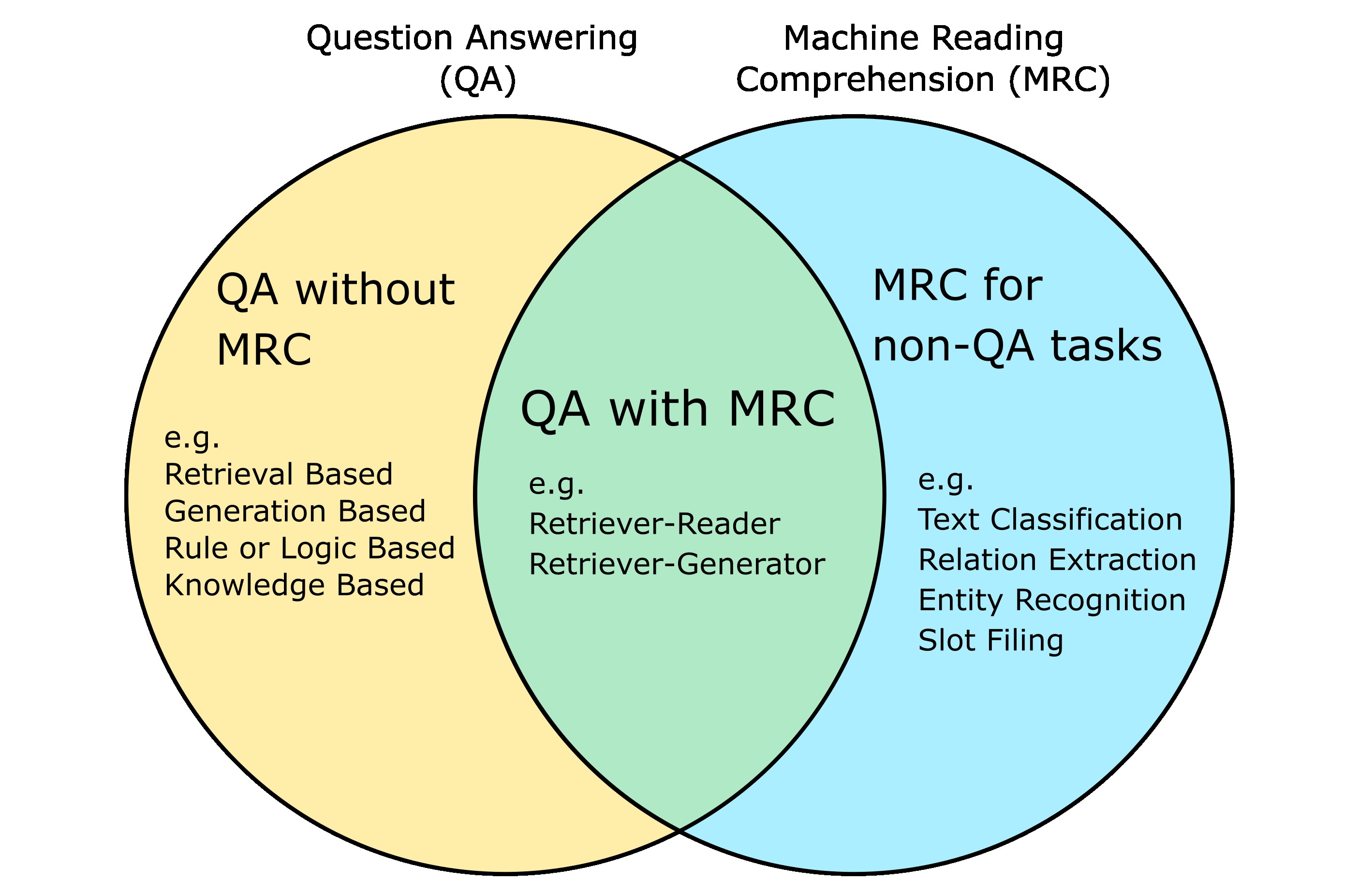
Figure 5: Relationship between Question Answering and Machine Reading Comprehension.
Practical Question Answering with MRC:
The standard formulation of many Machine Reading Comprehension tasks is technically Question Answering, but is not a very practical form of it. Exams do not provide a good representation of real-world questions and textual context is rarely available in practical settings.
We usually do however, have access to a large repository of knowledge, usually the internet. The necessary “context” can be generated from scratch by retrieving documents that are likely to contain the answer, using Information Retrieval (IR) techniques like TF-IDF.
This makes it possible to answer general questions without any context given, i.e. Open Domain Question Answering. The SearchQA dataset provides a good benchmark this kind of QA.
Classification of Open-Domain QA Techniques:
How to Build an Open-Domain Question Answering System and the paper Question and Answer Test-Train Overlap in Open-Domain Question Answering Datasets provide a good classification for Open Domain QA.
The Generation based QA described above also performs open domain QA by definition, as it does not rely on reading passages at all.
For practical QA where context is not given, we can abstract the different components into three types:
1. Retriever:
Use Information Retrieval techniques to search some relevant passages that might contain the answer. Traditionally this has been done using IR techniques like TFIDF.
Recently techniques based on deep learning and embedding vectors have also been applied. Dense Passage Retrieval for Open Domain QA used BERT embedding with cosine similarity to retrieve documents.
2. Reader:
Use Span-based Machine Reading Comprehension to extract a relevant answer span from a retrieved document.
Recently, approaches that rely on large language models like BERT, ALBERT, SpanBERT, LUKE, XLNET for encoding the passages have some of the best performance on both the Squad 1.1 and Squad 2.0 datasets. E.g Retrospective Reader for Machine Reading Comprehension.
3. Generator:
A module which generates an answer given a question. This can be either conditioned on a given context, like in Free Form based MRC, or a purely generative approach which only utilises the model parameters to generate an answer.
By composing above modules, we can construct different types of QA pipelines utilising MRC:
1. Retriever-Reader:
Search for a relevant passage. the a perform a “reading” step to extract the answer span from the context, and return it as an answer.
2. Retriever-Generator:
Search for relevant evidence passages, then perform a generation by conditioning on the evidence text to generate a unique answer that does not exist in the retrieved passage. This can be used to generate new information that does not exist in the passage, or simply rewrite answer spans extracted from the passage. More details in the S-NET paper.
QA formats that do not use Reading Comprehension:
There are some forms of Question Answering that do not rely on understanding a given textual context.
1. Retriever Only:
Information Retrieval based approach that basically works like a search engine. This attempt to answer a question by simply searching for a documents or passages and return relevant ones as-is. BM25, TF-IDF, Full-text search based retrieval methods fall under this.
2. Generator Only:
Use a generative model to synthesize answers from memory. Similar to answering questions in a closed-book exam. This is a non-MRC based approach, as it it does not rely on retrieving passages at all.
Purely generative question answerers like GPT that do not rely on passages are able to answer questions without understanding text. The knowledge to answer the question is entirely encoded in the model parameters.
There are also some answering techniques that do not fall under the Retriever Reader Generator framework.
3. Knowledge Based:
Methods that will query a knowledge base to answer a question by converting the question to a SQL or SPARQL query also do not fall under MRC. See Knowledge Based Question Answering.
4. Rule or Logic based:
Some types of questions can be answering simply by applying rules or logical reasoning. For example, numeric type questions like “What is 2 + 2?” can potentially answering by parsing the query and running the calculation 2 + 2 to return 4.
Reading Comprehension for non-QA Tasks:
There are many general tasks in language understanding that test some aspect of text comprehension, such as Part-of-Speech Tagging and Relation Extraction, etc. The information from these tasks might even be a pre-requisite to answer certain harder question for the more complex task of Question Answering.
Thus, a trained Question Answering model could possess some ability to solve other language understanding tasks, and might even become good at it if provided task-specific supervision. This is already demonstrated in the context of Prompt-based learning where language models are able to solve many different NLP tasks out-of-the-box.
We can try to exploit this by teaching a question answering system to solve other seemingly unrelated tasks; by simply mapping them to a QA format.
For example, I could ask a model the Question “What are the Verb tokens in the passage?”, and pass it a sentence “I like to read books.” as a textual context. The model can then be trained to return the answer “read” as a list of all verbs in the passage.
This was first done in Dynamic Memory Networks for Natural Language Processing, the authors proposed a model that jointly solves sentiment classification, question answering and part of speech tagging via QA task formulation. Similarly, Multitask Learning as Question Answering applied LSTMs with Attention to jointly solve 11 tasks including question answering; by mapping them to span-based reading comprehension.
For most of the above tasks, the answer words are either copied from the context, copied from the question or generated from scratch from a vocabulary. For classification, the answer is just a word copied from the question. The Questions are generated via human-defined templates.
Benefits of this approach:
- It allows us to leverage state-of-the-art advancements in MRC model architectures as well as utilise existing Question Answering datasets via pre-training.
- It allows us to use a single model type and input-output interface for completely different tasks. This allows to share knowledge between tasks via multitask learning.
- No need to pre-define the number of prediction classes as the label is directly encoded in the query text. This allows the model to deal with previously unseen labels at test time, thus allowing zero-shot learning.
- Useful for tasks where there is a dependency or hierarchical relationship between predictions, such as event extraction or relation extraction. This is done via multi-turn QA where prediction from one task is used to generate a query for the next task. We can also confirm the results of previous steps by performing the questioning in reverse.
When is it useful?
Although it is possible to pose many tasks as question answering, the question still remains whether or not it is an optimal formulation in every case, as opposed to modelling the task some other way.
The paper Question Answering is a Format; When is it Useful? tries to investigate this problem.
The authors mention 3 cases where QA formulation can be practical:
- Fulfilling human information needs. Creating systems where a human can only query the system in natural language. For example, voice assistants and chatbots.
- To simplify complicated annotation tasks by allowing crowd workers to pose them as questions and answers. Especially when some tasks like reading comprehension and visual question answering are hard to formalise.
- Effectively performing transfer learning by leveraging the same model for multiple tasks. This has been demonstrated in Kumar et al., 2016 and McCann et al., 2018.
According to the authors, the Question Answering format requires us to provide a Question as an additional input in addition to the Context. Therefore any task for which understanding the meaning of the Question is critical to solving the task, can be said be to be properly posed as a Question Answering problem. This can be true for tasks where the required information to be extracted can not be enumerated in a simple way, such as in Visual Question Answering.

Figure 6: Example queries in the CLEVR dataset which require complex question understanding.
On the other hand, simple static questions based on templates e.g. “What is the sentiment?” or “What is \<slot value\>?” are used frequently for QA based task formulation in the literature. Technically, these questions could be replaced by an arbitrary word or integer, and the task itself will not change at all. Since question understanding is not necessary, the model can simply memorize the question template, thus making it liable to overfit. Thus it could be argued that such tasks are not suitable for Question Answering in the first place.
Still, this format still has advantages in term of knowledge transfer, few/zero shot learning and simplifying task dependencies. Future work in QA task formulation should focus more on gain in these areas as well as discover sufficiently difficult tasks where question understanding can be useful.
More on Question Generation
Most approaches for question generation for QA task formulation are based on human-generated templates. These templates may either be either fixed or generated dynamically by filling in certain slots. However, not much work has been done on generating effective questions outside of templating.
Description Based Text Classification with Reinforcement Learning proposed an extractive and abstractive approach for query generation in addition to templates. For extractive queries, a relevant span from the input sentence is taken as a query. For the abstractive approach, a free form query is generated by conditioning over the input text.

Figure 7: Example of dynamic queries generated for the rec.autos class in the 10news dataset. (Source: Chai et al. 2020)
In the related task of prompt based learning however, learnable or soft prompts have been utilized extensively. So there might be some hints from that area that are applicable to question generation.
On the other hand, Question generation is well-studied as a task it itself in the context or MRC; as in Yuan et al., 2017, Du et al., 2017, Zhao et al., 2018 and Kumar et al., 2019. It has also been used to perform semi-supervised question answering, as in Semi-Supervised QA with Generative Domain-Adaptive Nets.
Single-turn vs Multi-turn Formulation
Some language tasks require the output of a pre-requisite task as an input to solve them. For example, relation extraction requires the named entities in the text as an input. Event extraction requires us to solve a sequence of tasks consisting of trigger word extraction, event type classification and finally argument extraction. Slot filing might require information from previously.
These tasks may also have some information overlap which would make it more efficient to solve them jointly. A single question-answer sequence is then not sufficient to solve these inter-connected tasks.
Generally, such tasks which consist of hierarchical dependencies are framed as multi-turn question answering where we question the model multiple times to extract the required information from the context.
The first question is usually a static query. Based on the result of that query, we can ask successive dynamic queries by filling in the required slots with information from previous steps. The dialog tree as well as the templates have to be defined manually for this. Also, Reinforcement learning may be used in this scenario to optimise over the multiple decision steps taken.
Relation to Prompt based learning
There is a related trend of using large language models like BERT and GPT to directly solve downstream tasks without any task-specific fine-tuning at all. This is done by constructing special queries called prompts which are able to extract specific kinds of knowledge from language models. Compared to QA based models, there is a stronger focus on how to utilise existing knowledge in large language models.
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing provides a good survey on prompt based learning methods.
Due to the query based formulation of tasks, both approaches are applicable in the few-shot or zero-shot setting.
Still, there are some core differences:
- In reading comprehension the model is given the question and context as separate inputs, while in prompt based learning a single input which contains all the information to solve the task.
- Reading Comprehension has more variety in answers type formats (span based, multiple choice, etc). In prompt based learning the only output is a probability value from 0 to 1 assigned by the language model.
- Given some task-specific data, it is possible to fine-tune the prompts while keeping the language model intact. This is not very well explored QA based task formulation, which is still mostly template based.
Task Examples
In this section I will list some works that formulate different tasks as Reading Comprehension based Question Answering.
Text Classification
The authors encode and concatenate an input text and a label description query as pass to a BERT model to make a binary decision for that label. The queries are either static descriptions from wikipedia definitions, or dynamically generated from the input text. This approach enables zero-shot text classification since number of classes is not necessary to be known in advance.
Event Extraction
Event extraction is the task to identify the proper event trigger token, classify it into an event types, then extract additional argument tokens for that event type.
As a first step we perform event trigger extraction as a classification step. For each trigger, we have a set of arguments for which we generate a question each.
Then for each argument, we concatenate the corresponding question and input text and pass it to a BERT model to extract each argument token.
Questions types are divided into a query topic expressions and a context dependent expressions. The query topic expressions are generated via rule-based templates. The context dependent expressions are generated as an unsupervised translation task or style transfer. The training process for which requires a large number of descriptive statements and unaligned question-style statements.
They use a multi-turn QA framework with 3 steps. First step is to extract all trigger words using a question. Second step uses questions to classify each trigger word into event types. Finally in the third step we ask a question to extract each argument for that trigger word.
Instead of question form queries they use statement form while also using <POS> tag to query for a given position token and : to encode subclasses.
Entity Linking
A standard approach in entity linking is to find entity mentions first and then find their corresponding entities. This approach is limited as knowledge of potential entity candidates can be useful to detect mentions. The authors define an approach that retrieves a list of likely entity candidates first, then extracts the relevant mentions by using the candidates as “queries” for a span-based reading comprehension task.
In this problem, a candidate entity then becomes the “Question” and the corresponding mention becomes the “Answer” for the task.
Emotion Cause Pair Extraction
This task is similar to entity and relation extraction, except that the prediction units are entire sentences rather than token spans. There are two entity types; emotion and cause, and a single relation type which is an emotion-cause pair.
A multi-turn system is used to extract emotion-cause pairs. The authors define simple template to extract emotion and causes in the first step. In the second step, they use a slot-filled template to extract causes given each emotion and emotions given each cause. Finally in the third step, they use the same templates in reverse to confirm the previous predictions.
Coreference Resolution
CorefQA consists of a mention span extraction step followed by a reading comprehension based mention linking step to find antecedent coreference pairs.
Given a mention, a query is generated by simply placing a <mention> tag around the target mention.
This two-step approach covers for the weakness of the mention extraction step, since the reading comprehension step can still discover new mentions which the mention extractor missed. Also, it allows effective use of context for both source and target mentions.
Slot Filing and Dialog State Tracking
The authors utilize reading comprehension with slot filing to improve cross-domain functionality by transferring the information of the same slot to multiple domains effectively. The base model is a simple BERT for span extraction.
The authors define 3 types of query generation techniques given a slot name. The first approach uses a simple slot description, the second approach uses back-translation to Chinese and back, the third approach extends the first one by also adding two examples for that slot type.
The authors use reading comprehension to solve the slot-filing aspect of Dialog State Tracking. To solve the different types of sub-problems needed for Dialog State Tracking the authors utilize both span based and multiple-choice questions.
For each slot type a template-based question is used to extract the corresponding slot span. The answer is either an extracted span or a multiple-choice answer depending on the slot type, or both.
Entity and Relation Extraction
The authors define relation extraction as a reading comprehension task. It is assumed that entities are already given and relations need to be predicted.
A query template is defined for each relation type, each of which has a slot for a head-entity. Given a relation type, we simple run the query multiple times for each entity in the context.
This approach can be extended to unseen relations by defining new query templates on-the-fly. If the underlying language model is good enough, then this approach can even generalize to new descriptions of existing relations. For example: cracked → deciphered.
Both pipeline and joint entity-relation extraction methods have a limitation in that they cannot take into account hierarchical dependencies between different relations and entities, as well as cases where multiple entities are involved in a relation such as (Elon Musk, CEO, SpaceX, 2006). Such relations cannot be represented effectively using triplets alone.
In above case, entities need to be extracted successively in order to gain the complete information, such as: Person → Company → Position → Time.
Generally for simple triplet extraction, two-turn QA is sufficient, one for head entity and one for tail entity. For the above case however, multi-turn question answering is required.
First, a fixed template question is asked to obtain a head entity. Then this entity is used in a slot-based template as extract successive entity. Each extracted entity may trigger additional questions where previously extracted entities are inserted into the slot elements. This process is continued until the entity relation set is extracted.
The question templates as well as entity hierarchies has to be defined in advance for each type of relation set.
Since there is a dependency between predictions, a reinforcement learning framework is used to optimize the model.
The authors also propose a new dataset called RESUME which highlights these difficulties in contrast to existing datasets like ACE2004 or ConLL.
The authors improve the head entity extraction step for relation extraction by asking a diverse set of questions for each entity type, then using an ensemble over the answers to generate a final prediction.
Then, given a head entity, a prior distribution is used to filter out potential relation types to extract, rather than enumerating over all possible relations.
Finally, they use the same ensemble step by asking a diverse question set for each relation to extract the tail entity.
In order to ask diverse questions, multiple templates are created for each relation type.
Named Entity Recognition
A standard BERT procedure is used to extract multiple overlapping entity start and end spans given a question and context. For each label types, a natural language question is generated. To generate questions, they used text from annotation guidelines as reference.
The authors experiment with different rule-based methods for query creation such as using wikipedia definition, annotation guideline notes, templates as well as using just keywords and synonyms. Annotation guideline notes tend to perform the best since wikipedia tends to be general.
The authors tackle low-resource Named Entity Recognition by using a pre-trained reading comprehension QA model and fine-tune it with a small number of labeled entity examples. Thus, Few-shot or Zero-shot learning is achieved for NER by leveraging pre-trained QA models.
To extract entities, various template-based queries are generated for each entity type, by incorporating the appropriate question words in the template.
Aspect Sentiment Triplet Extraction
Similar to Emotion Cause Pair Extraction, it is modeled as a multi-turn question answering task. There are two entity types on the span level; aspect and opinion as well as two relation types between aspect and opinion pairs; positive or negative.
Queries are defined via templates. A static query is used to extract aspect and opinion spans, then a slot-based query is used to extract aspect given opinion and vice versa. Finally, for each link, we create a query with 2 slots to predict the sentiment; positive or negative.
Summary
Machine Reading Comprehension is a framework for language understanding that can be used for answering open domain questions when used in combination with a document retrieval method. Question Answering itself is not limited to Reading Comprehension but most of the best-performing QA models rely on it.
Reading Comprehension can also be seen as a general format for posing many natural language understanding tasks in an alternative way. This is achieved by reformatting these tasks as question answering given a textual context. This formulation is mainly useful in multi-task settings and few-shot learning scenarios, as well as situations where there are multiple tasks to solve with complicated dependencies.
Future work in this paradigm should focus on building more sophisticated question generation techniques, improving performance in zero-shot scenarios, and solving more complex tasks which could benefit more from QA formulation.
References
- Neural Machine Reading Comprehension: Methods and Trends
- A Survey on Machine Reading Comprehension: Tasks, Evaluation Metrics, and Benchmark Datasets
- Question Answering vs Machine Reading Comprehension (QA vs MRC)
- SQuAD: 100,000+ Questions for Machine Comprehension of Text
- How to Build an Open-Domain Question Answering System
- NLP-progress: Question Answering
- Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
- The Natural Language Decathlon: Multitask Learning as Question Answering
- Prompting: Better Ways of Using Language Models for NLP Tasks
- Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
- Question Answering is a Format; When is it Useful?
- VQA: Visual Question Answering
- QA Formulation Task Specific Examples