Overview
The internet is the largest public repository of information available to us. Most of the data on the internet exists in the form of web pages, which are structured documents that are rendered by a web browser to be read by humans. These pages are rendered in a way that makes the information easy to understand visually, but difficult for computers to parse.
Websites about products and services often have a wealth of information in the form of key-value pairs, but these are generally difficult or time-consuming to parse into a structured format.
For example, in the screenshot below from the Tesla website, a human reader can visually associate the field of “Top Speed” with the value “135 mph” for the Tesla Model Y. However, it is difficult to write an algorithm that can reliably do this without prior knowledge of the underlying structure of the web page.
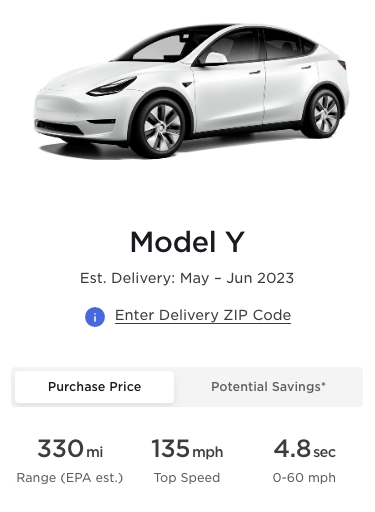
It is not usually possible to access the underlying database containing the data. Thus, the only way to obtain this information programmatically is by processing images of the rendered web page or by parsing the underlying HTML markup.
Traditionally web scraping is done to parse the HTML markup to extract the required information. Unfortunately, the structure of web pages is different across websites and it is difficult to write scraping logic that is applicable to all types of pages.
In this article, I will describe a recent deep learning technique that allow us to query HTML markup directly. This makes it easy to programmatically access desired values from web pages by designing “questions” or “prompts” that ask for certain information.
Background: About Document AI
Large Language Models (LLMs) like BERT can perform a wide variety of language-related tasks when fine-tuned on relatively small amounts of task-specific data.
A caveat is that these models only work on natural language. With structured documents like Web pages and PDF however, most of the valuable clues for extracting information exist in the visual layout and styling. Thus, it becomes necessary to leverage not only textual, but also the visual and layout information for effective information extraction.
Recently, there has been an interest in adapting these LLMs to work in non-text modalities like images and markup. One such line of research by Microsoft focuses on extending BERT-like models so they can be pre-trained on scanned documents and HTML markup to learn the structure of web pages and scanned documents.
This area of study is now dubbed as Document AI. By leveraging multiple views of the same information, these models when fine-tuned can outperform text-only LLMs in some document-based information extraction tasks.
Image and OCR based Models
The LayoutLM family of models is applicable to scanned documents, and it leverages tesseract OCR under the hood. It combines features extracted from OCR as well as visual features from the image to effectively model the document structure. These are effective at extracting information from screenshots of tables, pdf files and scanned documents.
These are trained on datasets like DocVQA.
Markup based Models
Web pages already have the text and and layout encoded in the form of an html file, thus using OCR on these is a bit redundant. MarkupLM is an extension of BERT that uses html DOM attributes as additional features to embed the words on a webpage. This is directly applicable to raw html.
MarkLM is restricted to html only information but other models like TIE use both visual and markup information in a multimodal fashion.
Question Answering on Documents
Techniques for extracting key-value pairs from web pages have been studied for a while. Datasets like SWDE define an ontology for attribute extraction across a few verticals like automotive and education.
Models trained on such datasets will accept an html string as input and return the tag text corresponding to various attribute values like price, mileage, model, etc. Such models are limited to a fixed category of attributes on which they are trained on, and extending to new domains and verticals will require additional training data and model development effort.
Questions are a natural way for humans to query information, and being able to answer these questions correctly is a major goal of Artificial Intelligence research.
Reading Comprehension based Question Answering allows us to input a textual context and ask a question about that context. In another post, I have written an overview Reading Comprehension based QA.
Architecture of MarkupLM
MarkupLM is an extension of BERT, where in addition to textual tokens, the model also utilizes the Xpath of each token.
The Xpath of a html tag defines the path from the root node to that tag in the DOM Tree of the HTML page. It can uniquely identify each tag in a document.
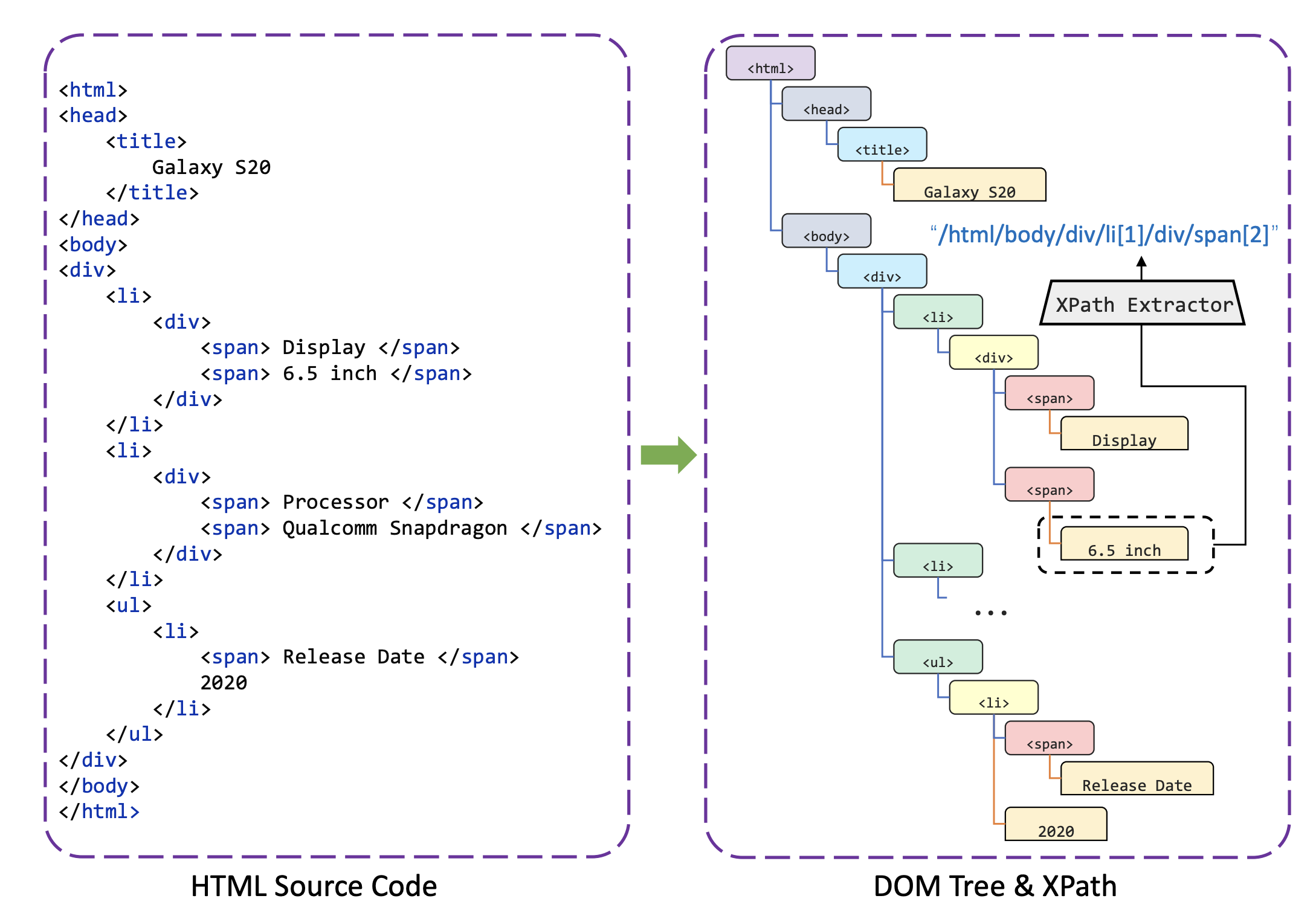
In the above example, the xpath /html/body/div/li[1]/div/span[2] uniquely identifies the tag containing the term 6.5 Inch.
The model computes an embedding for each xpath pattern and combines these with the token embeddings to make the final prediction for each token.
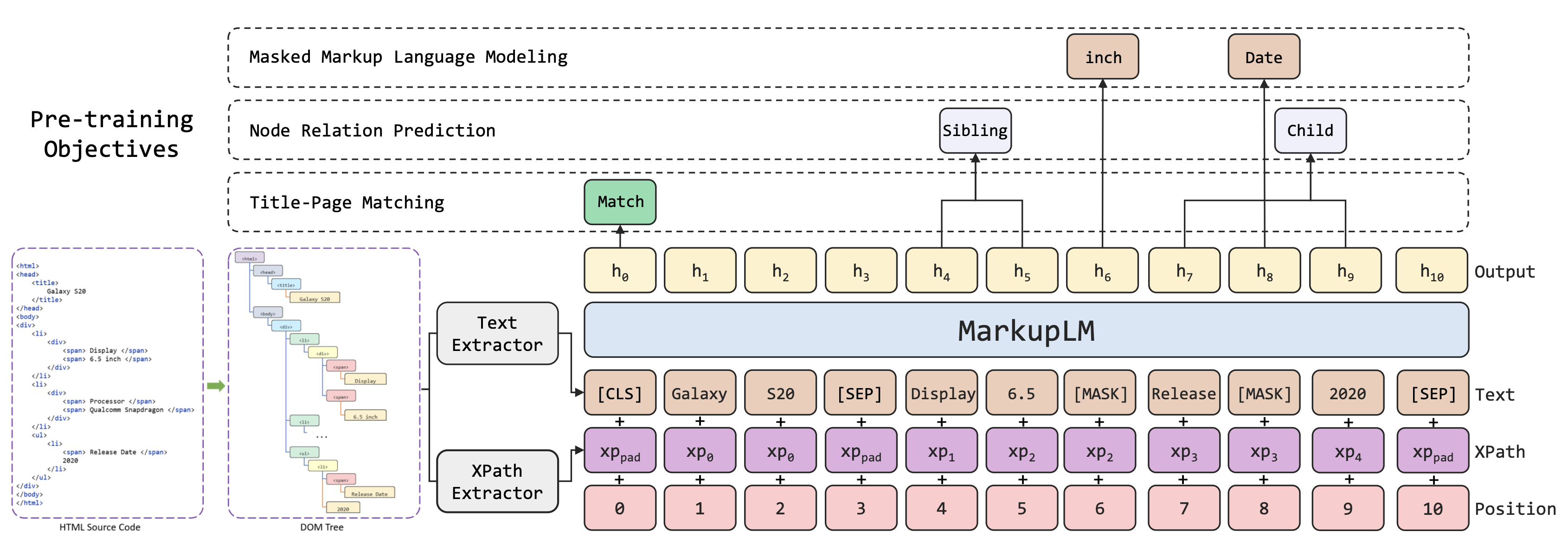
Pre-training:
Like the vanilla BERT, MarkupLM is pre-trained on large amounts of unlabeled HTML documents. The model is trained on 3 pre-training objectives in a self-supervised manner. The CommonCrawl corpus is used for pre-training.
Masked Markup Language Modeling:
Similar to Masked Language Modeling except that xpath tokens are also used to help predict the masked word tokens.
Node Relation Prediction:
Given a pair of html nodes, the task to predict the relationship between them. This can be parent, child, sibling, ancestor, descendant, etc.
This allows the model to learn about document structure.
Title Page Matching:
The text in the title tag is used as a proxy for the page title. The model is then trained to predict the page title given the rest of the document.
This allows the model to learn about high-level semantics and title level information.
Fine-tuning:
The model is fine-tuned on two tasks.
Attribute Extraction
A task based on the SWDE corpus. Given a webpage about a product or service, the task is to predict the values of some pre-defined attributes. The attributes depend on the product category, for a total of 8 categories and 32 attributes.
As an example, The camera category has the attributes model, price and manufacturer.

Question Answering
MarkupLM can be adapted to the reading comprehension task where we use an HTML string as the context instead of a textual paragraph.
Thus, Instead of hard-coding the ontology and range of attributes in advance, we can simply ask questions about a given input HTML string. We can then query about any attribute value or even ask more general questions about the site.
This zero-shot approach to HTML parsing will make make it more applicable to real life settings where training data is scarce.
The WebSRC corpus provides a training dataset for this exact use case.
The WebSRC Corpus
The WebSRC corpus provides a dataset of HTML and screen shots of webpages annotated with question and answers about various information in them. This allows us to train models that take an HTML as input directly.
It consists of html strings, questions, and answers to those questions annotated directly on the HTML tags.
WebSRC is mainly focused on short form information oriented answers, so it is not suitable for long form answers like in datasets like Squad.
Additionally, it only deals with What and Yes/No questions.
The target web pages are key-value pages, comparison pages and table pages.
Limitations:
- MarkupLM requires us to annotate the html directly which is not very intuitive and hard to manage as an annotation task.
- MarkupLM currently only uses the HTML, so it cannot use the visual layout information. Other models like TIE use both visual and markup information in a multimodal fashion.
- Not very suitable for long-form question answering.
Demonstration
This section contains a small code demonstration on how to apply MarkupLM to real sites.
Getting around the token limit:
Since MarkupLM is based on a BERT model, it has the same token limit of 512 tokens. This means that for long websites with a lot of text-context, the model cannot be applied directly to the entire page. There are a some approaches to get over it.
- Truncation
Truncation is a common approach but this leads to information loss. In the case of web pages, it is common for a lot of useful information to be in the footer at the end of the pages. However, it can be reliable for small pages of pages when the useful values are at the beginning.
- Sliding Window
A standard approach to deal with the token limit is to use a sliding window approach. Given a long document, we pass window of length 512 over it and generate predictions for each segment of the document. Then these predictions are aggregated via some criteria.
This approach is directly applicable to MarkupLM, thus allowing us to parse long webpages.
Setup:
Let us import the MarkupLM model and markup preprocessor from Huggingface.
MODEL_STR = "microsoft/markuplm-base-finetuned-websrc"
from transformers import MarkupLMProcessor, MarkupLMForQuestionAnswering
processor = MarkupLMProcessor.from_pretrained(MODEL_STR)
model = MarkupLMForQuestionAnswering.from_pretrained(MODEL_STR)Here we are loading the model "microsoft/markuplm-base-finetuned-websrc" which is MarkupLM fine-tuned on WebSRC for the question answering task
Load the HTML:
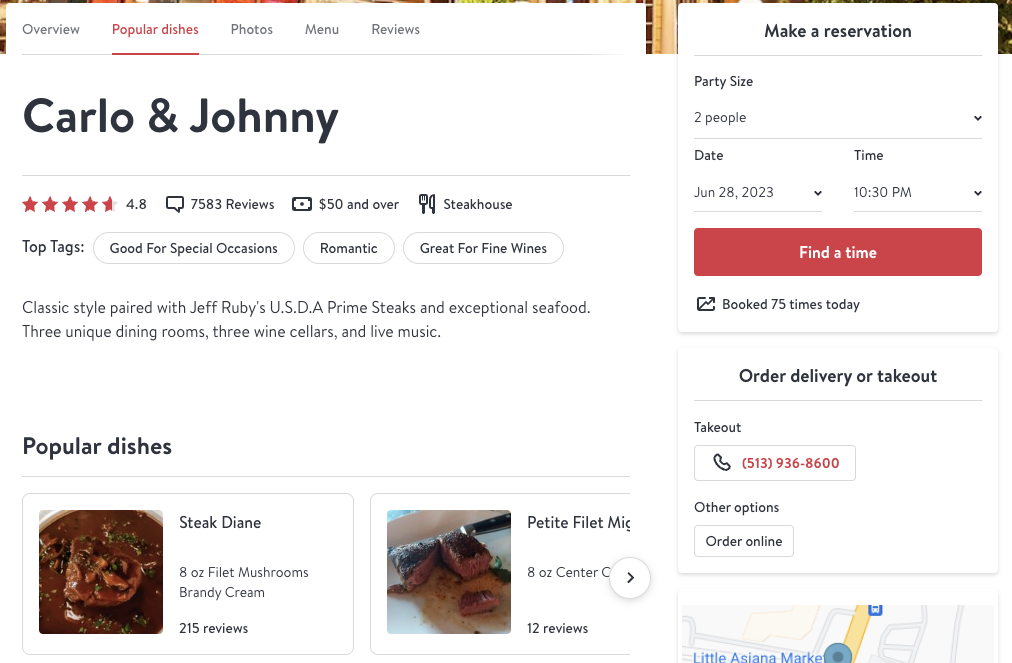
Here we load a web page of a restaurant. The page contains a lot of information at the beginning of the document as well as some information like address in the footer. The body mostly contains a large comment section which is unlikely to contain anything useful.
When using the requests library it is useful to disguise it as a browser. Otherwise the scraping might fail for a lot of websites.
import requests
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
}
sample_url = "https://www.opentable.com/carlo-and-johnny”
page = requests.get(sample_url, headers=headers)Extract Body with beautifulsoup
To remove some unnecessary metadata from the input, we extract the body using Beautifulsoup.
from bs4 import BeautifulSoup
soup = BeautifulSoup(page.content, "html.parser")
body = soup.find('body')BeautifulSoup could also be use remove other noisy tags like ‘css’, ‘script’, ‘svg’, ‘script’, ‘img’, ‘style’, ‘meta’, etc, as well at html tag attributes. However it is not necessary in this case as the markupLM preprocessor already does this steps before tokenization.
we then convert the body into a raw html string to use as the input.
html_string = str(body)Prepare the questions
There is a sidebar with a bunch of information in key-value format. This seems a good target for the model.
The WebSRC corpus MarkupLM is originally fine-tuned for only contains What and Yes/No questions, thus it is better to restrict out queries to this format.

We can construct queries to extract this information using a simple “What is” format. As an example, let’s use the following query to extract the phone number of the restaurant.
question = "what is the phone number?"Run the preprocessor
The preprocessor takes both the question and the html string. It tokenizes both the html text as well as the question and concatenates them. For each word in the text, it also calculates the Xpath of its tag to use as a feature.
A convenient aspect of the transformers tokenizer is that it can directly deal with sequences longer than 512 characters by applying a sliding window. We need to set some parameters for the sliding window.
stride: The number of tokens which overlap between two adjacent segments.
max_length: Basically the number of tokens in each segment, should be 512 or less. This takes into account the length for both the question and the segment.
return_overflowing_tokens: This needs to be set to true to perform the sliding window to return the extra tokens after max_length
truncation: Setting this to “only_second” will tell the processor to only truncate the html sequence and not the question.
padding: Set this to true to allow the processor to pad the last sequence to max_length
encoding = processor(html_string, questions=question, return_tensors="pt", truncation="only_second",
stride=100, max_length=512, return_overflowing_tokens=True, padding=True)We also do some post-processing to make the output compatible with MarkupLM.
del encoding['overflow_to_sample_mapping']
encoding['token_type_ids'] = encoding['token_type_ids'].fill_(0)Running encoding.keys() gives us
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])encoding is a dict-like object generated by transformer which contains the tokenized, truncated, and padded text mapped to token ids. The tokenizer also computes the html tag representation of each token in the form of xpaths, for use by MarkupLM.
We can check the dimensionality of generated tensors.
for k,v in encoding.items():
print(k,v.shape)Which should generate something like:
input_ids torch.Size([15, 512])token_type_ids torch.Size([15, 512])attention_mask torch.Size([15, 512])xpath_tags_seq torch.Size([15, 512, 50])xpath_subs_seq torch.Size([15, 512, 50])Here the 15 signifies the number of segments the document is broken into. Each segment consists of the sentence concatenated with. The second tensor signifies the max_length parameters we set before.
input_ids, token_type_ids and attention_mask are standard for any BERT model. They encode the token ids, token types and a mask that specifies whether or not to apply attention
The last two tensors are concerned the HTML structure. Specifically, each text is assigned a unique embedding that encodes its XPATH. This XPATH embedding then provides additional information about the HTML structure to the BERT model.
Running the model
We then apply inference on the pre-trained model.
import torch
with torch.no_grad():
outputs = model(**encoding)outputs consists of two tensors start_logits and end_logits each with a shape of (n_segments, max_seq_len).
print(outputs.start_logits.shape)
print(outputs.end_logits.shape)returns
torch.Size([15, 512])
torch.Size([15, 512])Basically each token in each segment is assigned two probabilities, one for being the start index of the answer segment and one of being the end index. This is standard for any Machine Reading Comprehension model.
However, these scores are not comparable across segments and we have to compute answers from each segment separately and combine the results.
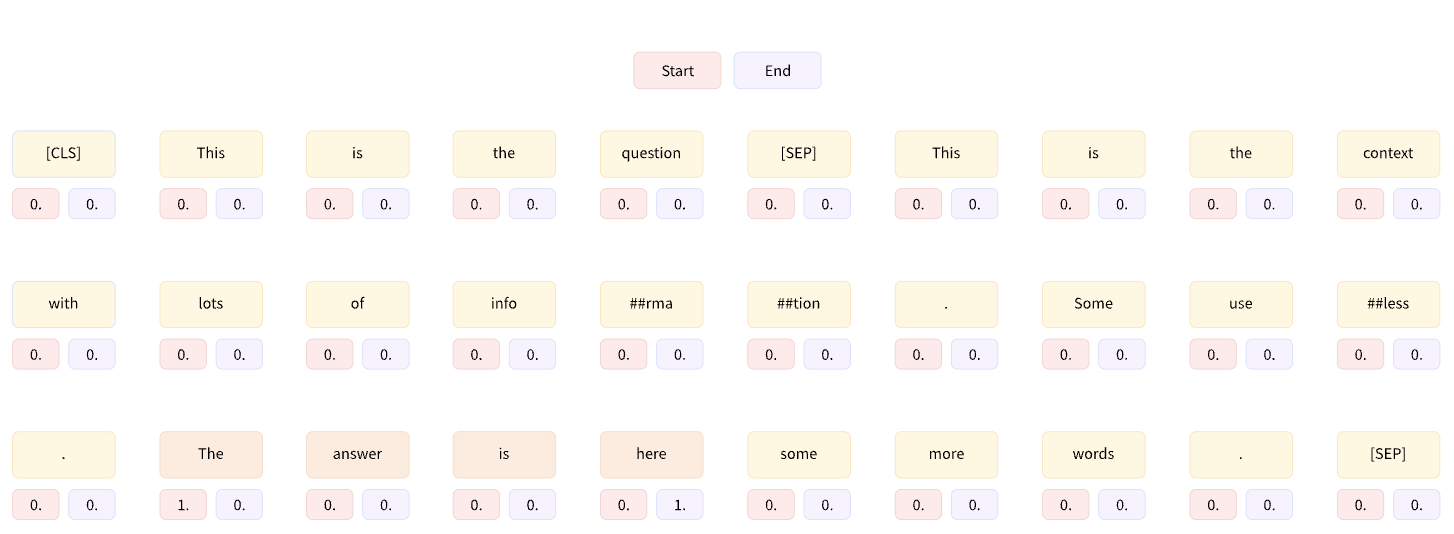
For reference, this tutorial by HuggingFace gives a good overview of how to utilize this probabilities to return confidence scores and predictions.
Answer Generation
We first convert the unnormalized logits to probability scores
start_probs = F.softmax(outputs.start_logits, dim=1).numpy()
end_probs = F.softmax(outputs.end_logits, dim=1).numpy()We can now use the above two scores to assign a probability to every possible span of text extracted from the original text. The probability for each span will be the product of its start token’s start probability and its end tokens’s end probability as assigned by the models.
However, we can save computational effort by only selecting the span with the maximum probability. To do this, we compute the token indices to the most likely start and end tokens, and also compute their corresponding span probability.
The following code does this for the first segment.
i = 0
start_index = np.argmax(start_probs[i])
end_index = np.argmax(end_probs[i])
confidence = max(start_probs[i]) * max(end_probs[i])
print(f"Span Start Index: {start_index}")
print(f"Span End Index: {end_index}")
print(f"Span Confidence: {confidence:.4f}")This gives us:
Span Start Index: 307
Span End Index: 314
Span Confidence: 0.9937Finally, we can construct the answer
predict_answer_tokens = encoding.input_ids[0, start_index : end_index + 1]
answer = processor.decode(predict_answer_tokens, skip_special_tokens=True)
print(f"Answer: {answer}")Which returns:
Answer: (513) 936-8600Predicting Over all segments
Depending on the question and page, the answer may not always exist at the beginning of the page. To cover the entire document, we can use the same approach to extract answers from each segment, and aggregate them.
It is also necessary to differentiate noisy answers from correct ones. We can use some criteria to filter out answers in advance.
- The start index occurs before the end index
- The answer is not too long.
- The answer span does not include the question itself.
- The answer has a minimum confidence score
We put all of these criteria together in the following code to iterate over all page segments and filter out the results.
# We also calculate the index where the question ends, for filtering answers
question_index = encoding[0].tokens.index('</s>')
# Compute number of segments to iterate over
n_segments = encoding['input_ids'].shape[0]
# Maximum number of characters allowed in answers
max_answer_len = 50
# Minimum confidence
min_confidence = 0.9
import torch.nn.functional as F
import numpy as np
answers = []
for i in range(n_segments):
start_index = np.argmax(start_probs[i])
end_index = np.argmax(end_probs[i])
confidence = max(start_probs[i]) * max(end_probs[i])
if end_index > start_index and end_index - start_index <= max_answer_len and start_index > question_index and end_index > question_index and confidence > min_confidence:
predict_answer_tokens = encoding.input_ids[0, start_index : end_index + 1]
answer = processor.decode(predict_answer_tokens, skip_special_tokens=True)
answers.append({"answer": answer, "confidence": confidence})The answers variable then contains:
[{'answer': '(513) 936-8600', 'confidence': 0.9937179}]It seems that the other segments either did not contain the answer or the predictions were not confidence enough. This is good for us since we do not have to deal with figuring out which answer is the correct one.